


3. software 6-10
page : 175
http://download.savannah.gnu.org/releases/tinycc/
Index of /releases/tinycc/
download.savannah.gnu.org
[임베디드 레시피 요약 및 정리] Chapter 3. SW ① :: 컴파일~로드
Endian을 이해하지 못하면, 디버깅 시에 오류에 빠질 수 있으니 꼭 이해해야 한다.(※ 정말 endian 중요합니다. 설령 배웠더라도 정말 햇갈리기 쉬운 개념이라 꼭 10분~20분 시간내서 정확하게 뇌에서
velog.io
https://rasino.tistory.com/307#google_vignette
【 C 환경설정 】 VS code에서 C/C++ 코딩환경 구축하기
【 C 환경설정 】 VS code에서 C/C++ 코딩 환경 구축하기 요즘 파이썬(python)이나 자바(JAVA), javascript C# 등등 하이레벨 언어를 학습하던 사람들이 프로그래밍의 근간을 튼튼히 한다거나? 여러 가지 이
rasino.tistory.com
ADS는 ARM사에서 파는 ARM Developer's Suit 이다.
1. Little Endian과 Big Endian
- Endian을 이해하지 못하면, 디버깅 시에 오류에 빠질 수 있으니 꼭 이해해야 한다.
([※] 정말 endian 중요합니다. 설령 배웠더라도 정말 햇갈리기 쉬운 개념이라 꼭 10분~20분 시간내서 정확하게 뇌에서 재정립하고 진행하시는게 좋습니다.) - 0x12345678이라는 dword 데이터를 저장한다면,
- Little endian은 MSB가 상위주소에 저장된다. [0] = 0x78, [1] = 0x56, [2] = 0x34, [3] = 0x12
- Big endian은 MSB가 하위 주소에 저장된다. [0] = 0x12, [1] = 0x34, [2] = 0x56, [3] = 0x78
- Big endian은 사람이 읽기 쉬운 형태고, little endian은 ARM processor가 읽기 쉬운 형태다.
([※] 개인적으로는 저 [0], [1], [2], [3]을 어떻게 배열하냐에 따라(내림차순, 오름차순, 위로 쌓기, 아래로 쌓기 등) 인상이 확확 달라져서 MSB가 이름의 반대로 저장(little은 상위주소, big은 하위주소)된다고 외웁니다.) - 따라서 ARM processor는 default로 little endian을 사용한다. 하지만, co-processor 15번 CP15의 CR 레지스터를 설정해서 big endian으로 동작하도록 설정 가능하며 컴파일 할 때도 설정할 수도 있다.
2. 컴파일 (Compile)
2.1. 컴파일이란?
- 우리는 chapter 1에서 CPU는 단순히 약속된 bit pattern을 약속된 절차에 따라 수행할 뿐이라고 배웠다.
- 단, 이 bit pattern(native code, 기계어)은 사람이 읽기에 너무 불편하기 때문에 사람이 그나마 읽을만한 1:1 매칭이 되는 표기법을 만든게 어셈블리(assembly, mnemonic)다.
- 그리고 이 1:1매칭을 자동으로 해주는 ‘어셈블러’를 만들었다.
- 하지만, 프로세서마다 약속된 bit patten이 달라서 프로그램을 만들어도 프로세서 A에서는 동작하지만, B에서는 동작하지 않는 문제가 발생했다.
- 서로 다른 프로세서에 맞는 어셈블리를 만들어주는 편리한 존재에 대한 수요가 증가했고, 그렇게 개발된게 컴파일러다.
- 컴파일러는 C/C++같은 high level language로 코드를 만들면, 각 프로세서에 약속된 bit pattern으로 매칭될 수 있는 어셈블리를 만들었고, 어셈블러는 1:1 매칭을 수행해 적절한 기계어를 만들 수 있게 됐다.
- 결국 사람은 프로세서의 동작 원리나 약속같은건 신경쓰지 않고 그냥 C/C++로 프로그램을 개발하면 됐다.
- 크로스컴파일(Cross-compile)은 타겟보드의 프로세서(ARM)와 우리가 사용하는 host PC의 프로세서(x86-64)가 다르기 때문에 타겟보드에서 동작할 수 있는 바이너리를 host PC에서 생성하는 일련의 과정을 말한다.
2.2. 컴파일 과정
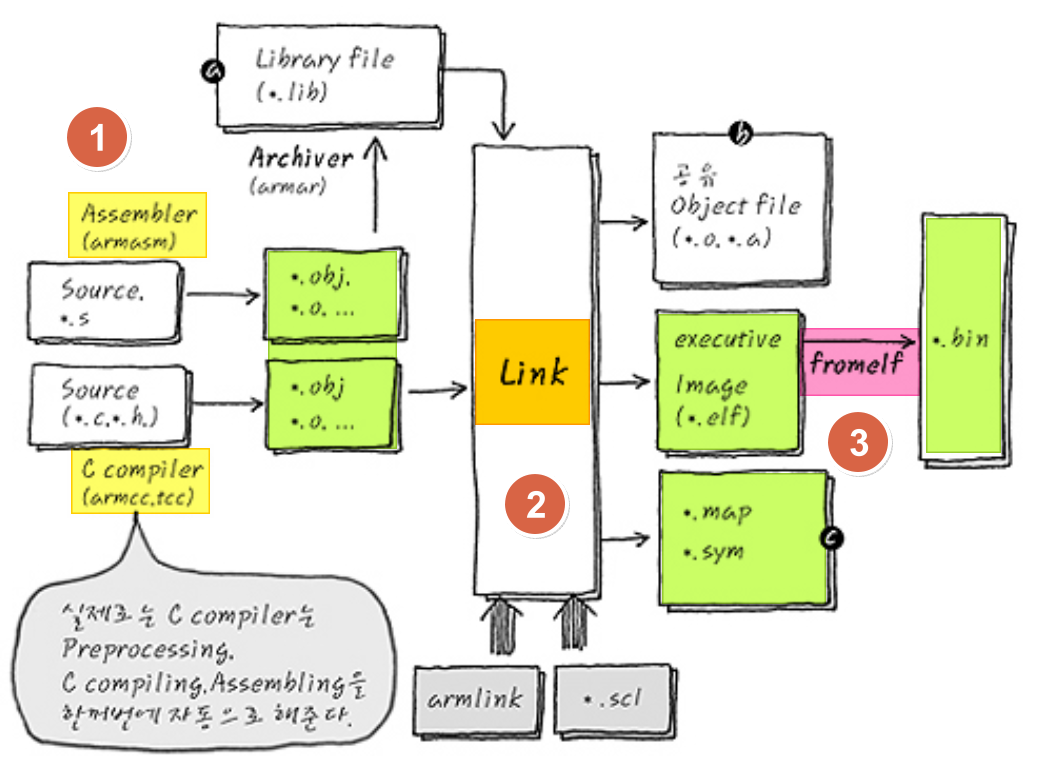
- 위 그림은 전체 컴파일 과정을 나타내며 간략하게 설명하면 다음과 같다.
- 전처리기(Preprocessor)가 컴파일을 쉽게 할 수 있도록 헤더파일과 매크로를 소스파일에 옮기는 최적화 작업을 수행하고 결과물로 .i파일을 만든다.
- 컴파일러가 .i 파일을 컴파일 해 .s 어셈블리를 만든다.
- 어셈블러가 .s 어셈블리를 .obj 목적파일(object file)로 만든다.
- 링커가 여러 .obj 파일과 라이브러리(.lib)을 묶고 엮어 하나의 실행 가능한 ELF(Executable & Loadable File)형식의 .elf 파일로 만든다. 이때 scatter loading 파일.scl또는 링커 스크립트(Linker script) .ld 를 통해 개발자가 원하는 메모리 구성을 가지도록 링커에게 정보를 줄 수도 있다.
- fromelf 또는 objcopy 같은 유틸리티를 사용해 최종 실행 바이너리 .bin 파일을 만든다.
2.3. 컴파일 실습 ①
[※] 본문에서는 ADS를 이용해 armcc 명령어와 tcc 명령어 등을 사용해서 컴파일 및 링크를 합니다. 하지만, 저를 포함해서 많은 분께서는 GNU의 ARM GCC 밖에 구할 수 없기 때문에 저도 GNU의 ARM GCC를 이용해서 실습했습니다.
#define TRUE 1
typedef struct {
char memberBool;
int memberInt;
char memberWord;
} memberType;
extern int add(int a, int b);#include "spaghetti.h"
int zi = 0;
int rw = 3;
extern int relocate = 3;
extern structure recipes[3];
int add(int a, int b);
int main() {
int stack;
volatile int local1, local2, local3;
local1 = 3;
local2 = 4;
local3 = add(local1, local2);
stack += local3;
return stack;
}
int add(int a, int b) {
return (a + b);
}[※] 위와 같이 본문의 코드를 입력한 뒤 각각 spaguetti.c와 spaghetti.h로 저장했습니다. (아참, 본문 코드랑 다르게 #define EQUAL = 안 하고 그냥 = 쓴 이유는, 그렇게 하면 이상하게 컴파일이 안 되서 불가피했습니다.)
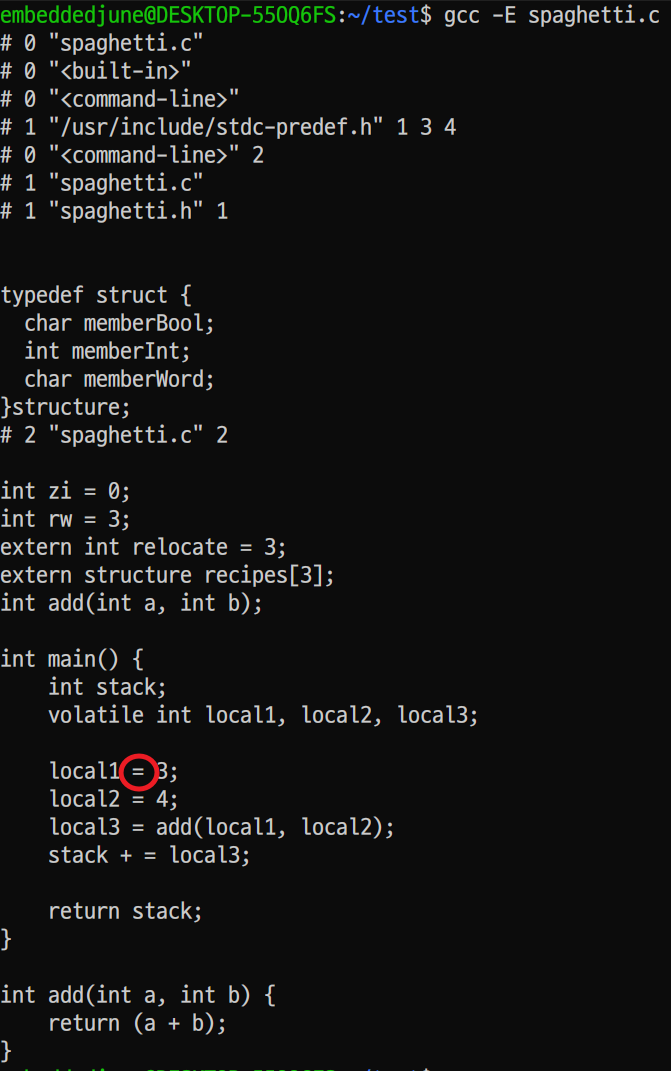
- arm-none-eabi-gcc -E 옵션을 통해 전처리를 수행한 결과입니다. 헤더파일 및 define 했던 것들이 코드에 들어가 적용된 모습을 볼 수 있습니다. 이렇게 단일 소스파일에 합쳐져 컴파일을 수월하게 해주는 게 전처리기의 역할입니다.

- -S 옵션을 통해 컴파일 후 어셈블리 파일만 뽑아낼 수 있습니다.
- R2에 3을, R3에 4를 집어넣는 모습을 보아 코드의 local1이 R2에, local2가 R3에 저장된 것을 알 수 있습니다.
- 스택이 0x16만큼 감소합니다 (상위주소 → 하위주소). 현재 main()에 지역변수가 4개있고 int형이므로 각각 4-byte씩 총 16-byte를 차지하기 때문입니다. STR 명령어를 통해 값을 저장합니다.
- LDR 명령어로 불러온 뒤 두 값을 더하고 최종결과를 AAPCS에 따라 R0에 저장합니다. 이제 스택에 저장된 값들은 필요없으므로 다시 0x16을 더한 뒤 return 합니다.
- Return 할 때는 LR이 가리키는 주소로 갑니다.
- 이 컴파일은 O2옵션을 줬기 때문에 add() 함수에 대한 최적화가 자동으로 이뤄졌습니다. 함수 호출 부분에서 최적화가 발생했음을 알 수 있습니다.
3. 링커(Linker)와 ELF
3.1. 변수의 생애주기
- auto
- 지역변수에 해당하며 블록 또는 함수 범위 내에서 선언돼 실행흐름이 범위를 벗어날 때 사라진다.
- extern
- Global변수에 해당하며 선언 이후 파일 끝까지 전체에서 사용할 수 있다.
- 프로그램 전체에서 사용 가능할 뿐만 아니라 다른 파일에서도 불러다 사용할 수 있다.
- static
- 위 auto, extern 변수 모두 static 선언이 가능하며 다른 의미를 가지게 된다.
- static auto의 경우 범위를 벗어나도 그 값을 유지한다. 단, 범위를 벗어난 경우에는 사용할 수 없다.
- static extern의 경우 프로그램 전체에서 사용 가능한 건 변함 없지만, 다른 파일에서는 불러서 사용할 수 없다.
- 따라서 static 선언은 값은 유지하되 범위는 국한시키는 속성을 부여해 C++의 protected와 비슷하다.
- volatile
- 컴파일러는 옵션에 따라 자동으로 연산을 최소화하는 방향으로 최적화를 수행한다.
- 이러한 최적화가 되려 개발자의 의도에 맞지 않게 실행흐름을 변경시키는 결과를 초래하기도 한다.
- 예를 들어, 같은 주소에 대한 연속적인 data write을 하는 burst transfer 중인 device가 있다고 할 때, 컴파일러가 최종값만 write 하도록 최적화 해버리면 중간과정의 data들이 유실되는 사고가 발생한다.
- 이런 경우를 방지하기 위해 volatile 선언을 통해 컴파일러로 하여금 '이 변수에 대해서는 최적화를 하지 말고 코딩된 그대로 실행하라'라고 명령한다.
3.2. Symbol과 영역
3.2.1. Symbol이란?
- Symbol이란, 메모리에 자신만의 고유 주소를 갖게 되는 단위를 말하며 링커가 인식할 수 있는 기본 단위다.
- Symbol == global 이라는 뜻을 가진다고 이해해도 된다. 함수, 전역변수, static 변수는 고유 주소를 갖기 때문에 소스파일 내 어디에서도 참조가 가능한 것을 떠올리면 쉽게 납득할 수 있다.
- 반면, 지역변수는 고유 주소를 갖고 있지 못하기 때문에 루틴이 종료됨에 따라 사라진다.
- 링커는 각 symbol과 symbol의 시작주소를 table에 저장하고 관리한다. 이 table은 컴파일 후 결과물로 나오는 .o 오브젝트 파일에서 확인할 수 있다.
3.2.2. 영역 구분 (RO, RW, ZI) (.text, .data, .bss)
- Symbol은 내부적으로 3가지 종류로 나뉘는데, 각 종류에 따라 메모리에 올라가는 영역도 달라진다.
- Read only (RO, .text)
- 읽기만 가능하고 수정할 수 없는 symbol을 의미한다.
- 대표적으로 const형으로 선언된 전역변수라던지, 소스코드 자체를 의미한다.
- 이 종류에 속하는 symbol은 메모리의 RO영역 또는 .text라고 부르는 영역에 속한다.
- Read Write (RW, .data)
- 읽기와 쓰기가 가능해 수정할 수 있는 symbol을 의미한다.
- 대표적으로 초기화 된, 초기화 값이 있는 전역변수가 여기에 속한다.
- 이 종류에 속하는 symbol은 메모리의 RW영역 또는 .data라고 부르는 영역에 속한다.
- Zero Initialized (ZI, .bss)
- 이름 그대로 0으로 초기화되는 symbol을 의미하며 대표적으로 초기값이 없는 전역변수가 여기 속한다.
- 이 종류에 속하는 symbol은 메모리의 ZI영역 또는 .bss라고 부르는 영역에 속한다.
- [※] C/C++로 코딩테스트 준비해보신 분들은 아시겠지만, 전역변수로 초기값 안 주고 코딩하는 경우가 많으실 겁니다. 자동으로 0으로 초기화해주기 때문에 편하게 사용하셨을 탠데요, 이런 변수들이 다 ZI 영역(.bss)입니다.
- Read only (RO, .text)
- 어떤 영역에 속하냐에 따라 저장되는 위치도 달라진다.
- RO영역은 항상 그 값을 유지하고 있어야 하고 수정될 일도 없으므로 ROM(Flash memory)에 저장된다.
- RW영역은 초기값을 가지고 있어야 하므로 ROM에 저장된다. 또한, 명령어에 따라 수시로 수정이 이뤄져야 하므로 RAM에도 있어야 한다.
- ZI영역은 메모리에서 0으로 초기화 될 것이므로 ROM에 저장할 필요가 없고 RAM에 저장된다.
- 개발자는 각 영역의 시작주소와 길이에 대한 정보를 링커에게 전달해서 원하는 주소에 영역을 위치시킬 수 있다.
- 이 정보를 담고있는 파일을 Scatter loading 파일 또는 linker script(링커스크립트)라고 부른다.
3.3. ELF format object file
- 컴파일 후 결과물인 .obj 오브젝트 파일은 ELF 형식을 따른다.
- 오브젝트 파일은 relocatable object file과 executable object file로 나뉜다.
- 여러 소스파일이 있을 때,각 소스파일을 컴파일 하면 각각에 대한 오브젝트 파일이 나올 것이다.
- 각 소스파일이 다른 소스파일에 있는 extern변수 또는 함수를 가져와서 사용한다고 가정하자. 그러면, 현재 컴파일 된 소스파일에는 해당 변수나 함수에 대한 정보가 없기 때문에 컴파일러는 구멍을 뚫어놓고 ‘링커야, 나중에 다른 파일에서 대응하는 symbol을 찾아서 구멍을 매꿔줘’라고 표시한다.
- 이렇게 구멍이 뚫려있는 상태인, 나중에 링커를 통해 재배치가 가능한 오브젝트 파일을 relocatable 오브젝트 파일이라고 부른다.
- 만일, 오브젝트 파일이 2개 이상이고 링크 과정을 거쳐야 한다면 -c 옵션을 통해 링커가 link 하지 못하게끔 해서 relocatable object file을 만들어야 한다.
- 오브젝트 파일은 크게 다음과 같은 4가지 section으로 구성된다.
- ELF Header
- Code section (RO, .text, .rodata)
- Data section (RW, ZI, .data, .bss)
- Debug section (.debug, .line, .strtab, .symtab 등)
- .symtab이 바로 symbol table이며 링크와 디버깅할 때 꼭 필요한 부분이다.

- [※] objdump 유틸리티를 사용해서 relocatable object file 내부를 덤프한 모습입니다.
- [※] 각 섹션의 .text 부분을 확인할 수 있습니다.
- [※] 상대주소와 opcode 그리고 어셈블리 명령어를 한 눈에 보기 좋게 확인할 수 있습니다.
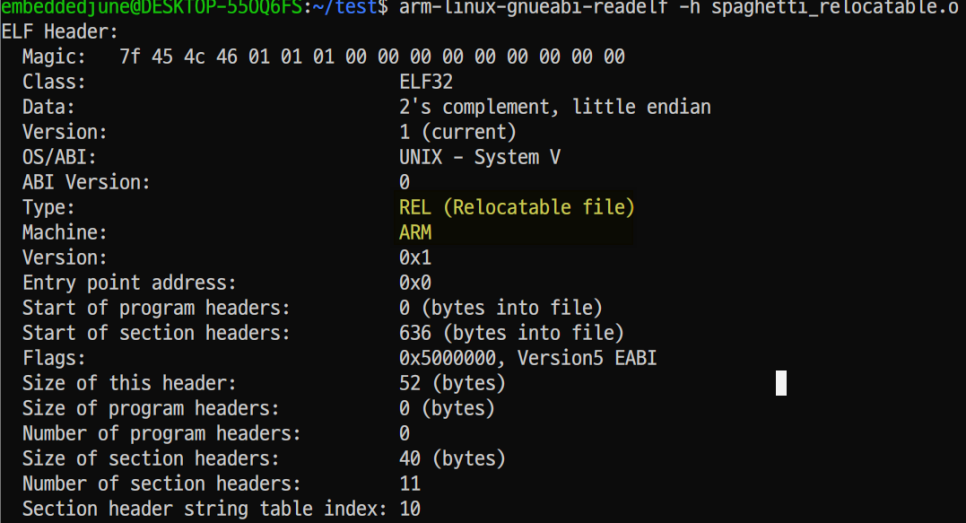
- [※] readelf 유틸리티를 사용해서 relocatable object file의 가장 첫 부분인 'ELF 헤더'를 덤프한 모습입니다.
- [※] 현재 object file의 종류가 REL(Relocatable file)이라는 점, ARM mode로 컴파일 된 점, 헤더 크기가 52Byte인 점 등을 확인할 수 있습니다. 본문 내용과 같네요!
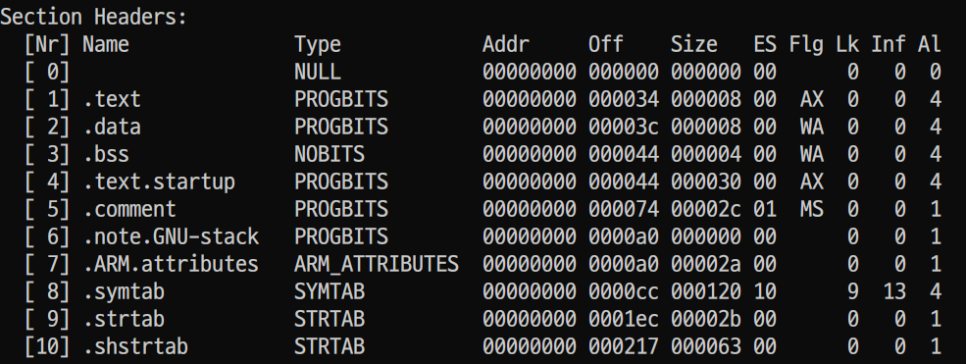
- [※] 본문에서 설명한 section들이 똑같이 들어있음을 확인할 수 있습니다.
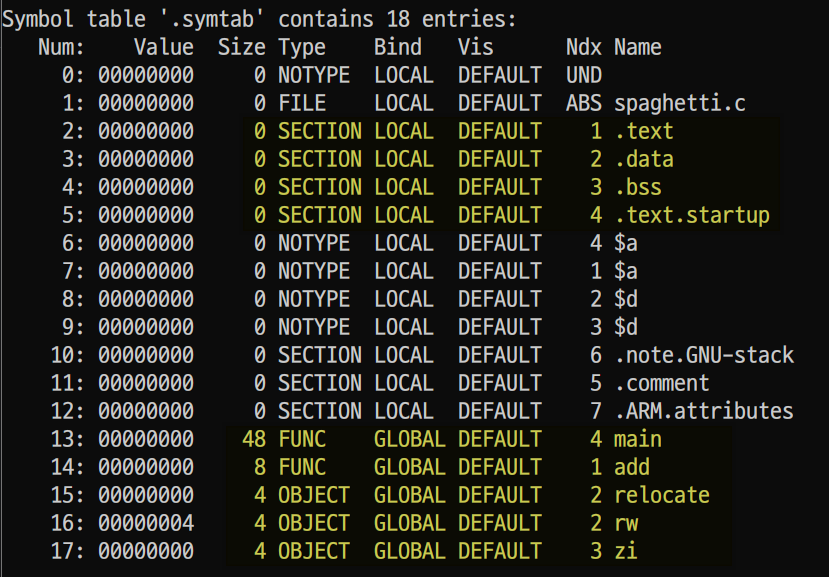
- Object file 속 symbol table의 모습이다.
- Num은 링커를 위한 symbol의 번호다.
- Value는 해당 symbol의 시작 offset 주소다.
- Size는 symbol의 크기다. Function(함수), object(전역변수)가 아닌 경우는 0이다.
- Type은 해당 symbol의 종류 (함수, 전역변수, section 등)를 나타낸다.
- Bind는 해당 symbol의 scope를 의미함 Global, Local, Weak를 나타낸다.
- Ndx는
- UND: 현재 file에서 사용되고 있지만 define은 없는 symbol
- ABS: Relocate 돼서는 안 되는 symbol
- 1은 .text, 2는 .data, 3은 .bss를 의미한다.
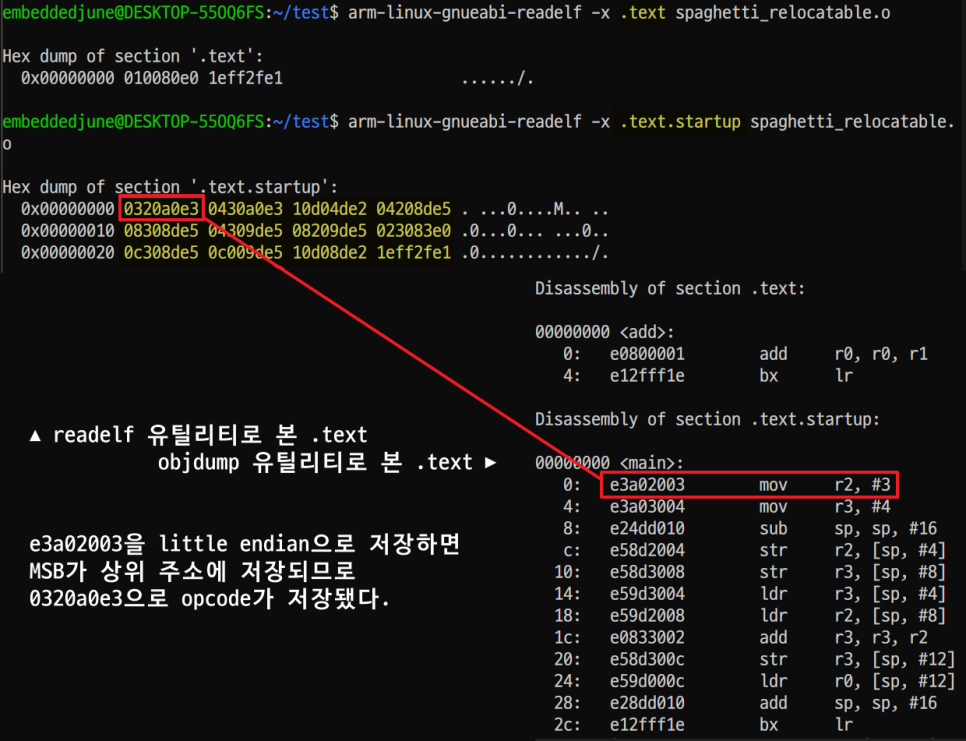
- [※] objdump로 확인해본 opcode가 little endian 형태로 .text에 저장돼있네요.
- [※] 본문 내용대로 Header 이후 opcode가 나오는 것을 확인할 수 있었습니다.
3.4. 링커(Linker)
- 우리는 앞서 symbol과 relocatable 오브젝트 파일의 내부 구조를 배웠다.
- 이제 링커의 역할과 executable 오브젝트 파일까지 배워보며 마무리를 해보자.
- 링커가 하는 역할은 다음 2가지로 요약할 수 있다.
- 여러 relocatable 오브젝트 파일들을 같은 section끼리 모아서 순서대로 정렬해 합친다.
- Symbol reference resolving을 수행한다.
- 앞서 relocatable 오브젝트 파일에는 ‘구멍’이 뚫려 있을 수 있다고 표현했다.
- 어떤 파일에 선언만 돼있고 사용하진 않은 변수라던가,
- 어떤 변수나 함수를 불렀는데 그 파일에 없고 다른 파일에 extern으로 선언돼 있다던가
- 이런 구멍들을 하나하나 찾아서 서로 연결해 매꿔주는 작업을 링커가 수행한다.
- 앞서 relocatable 오브젝트 파일에는 ‘구멍’이 뚫려 있을 수 있다고 표현했다.
- 이런 복잡한 작업을 수행하기 때문에 link 때 메모리와 시간을 많이 잡아먹는 것이다.
3.5. Scatter loading (Linker script)
- 위 2.2절에서 링커에 대한 설명을 할 때 scatter loading(또는 linker script)를 통해 개발자가 ㅡ원하는 메모리 구성을 가지도록 링커에게 정보를 줄 수도 있다고 설명했다.
- ADS에서는 sctter loading file이라고 부르고, GNU에서는 linker script라고 부른다.
- 메모리를 개발자가 원하는 대로 구성할 때는 두 가지 관점에서 봐야 한다.
- Load view : SW가 실행되기 전에 저장매체(ROM, Flash)에 저장돼 있을 때의 모습이다.
- Execution view : SW가 실행되기 위해 메모리(SDRAM)에 로드됐을 떄의 모습이다.
- 먼저, 앞서 RO, RW는 ROM에, RW, ZI는 RAM에 저장된다고 배웠는데, 프로그램이 실행되기 위해서는,
- NOR Flash의 경우 XIP를 지원하므로 RW만 RAM에 로드하고 ZI를 할당해야 한다.
- NAND Flash의 경우 XIP가 불가능하므로 RO, RW를 모두 RAM에 로드하고 ZI를 할당해야 한다.
- 따라서 로드하는 과정이 들어가기 때문에 load view와 execution view는 메모리 구조가 달라지게 된다.
- 그럼 위 개념을 가지고 scatter loading file을 작성해보자.
LOAD_REGION 0x0
{
EXEC_REGION1 0x0
{
spaghettil.o (+RO)
}
EXEC_REGION2 0x8000
{
spaghettil.o (+RW)
}
EXEC_REGION3 0xA000
{
spaghettil.o (+ZI)
}
}- 가장 바깥쪽 LOAD_REGION은 load view의 시작주소를 의미한다.
- Load view에서는 시작주소부터 RO, RW를 차곡차곡 차례대로 저장한다.
- 안쪽 EXEC_REGION1, 2, 3은 execution view이며 각각 RO, RW, ZI 영역의 시작주소를 의미한다.
- 0x0번지부터 RO영역이, 0x8000번지부터 RW영역이, 0xA000부터 ZI영역이 시작됨을 링커에게 알린다.
- 이때 RO영역과 Load view의 시작주소가 같다. 이를 Root region이라고 하는데, loading view와 execution view의 주소가 같은 영역을 말하며 scatter loading 파일에 꼭 하나씩은 있어야 한다.
'하드웨어 해킹 및 임베디드' 카테고리의 다른 글
| Chapter 7. Device control (0) | 2023.06.25 |
|---|---|
| SecOC(Secure On-board. Communication) (1) | 2023.05.16 |
| ELF format Object File에 관한 진실 (1) | 2023.03.14 |
| STM32 보드 임베디드 진행 전 (0) | 2023.02.19 |
| TELECHIPS社 TCC8925 안드로이드용 (0) | 2023.02.15 |

wtdsoul