Init은 리눅스 커널 부팅이 완료된 뒤 실행되는 첫 번째 프로세스다. 또한 동시에 Init은 커널이 직접 실행하는 유일한 프로세스다. 따라서 Init은 부모 프로세스를 가지지 않는 유일한 프로세스인 동시에, Init을 제외한 나머지 모든 프로세스의 조상이 된다. 이러한 특징으로 인해 Init은 아래와 같은 작업들을 수행한다.
Init이 하는 일
위 그림과 같이 Init은 프로세스와 시스템의 초기화와 관리를 수행한다. 우선 Init은 등록된 서비스 혹은 initrc에 기록된 백그라운드 서비스와 시스템 서비스를 실행한다. 우선 우리가 리눅스 상에서 GUI를 사용할 수 있도록 GDM, LightDM 등의 디스플레이 매니저를 실행한다. 백그라운드 서비스로는 파일을 필요할 때 문맥에 맞게 가져올 수 있도록 분류, 그룹짓는 tracker-miner가 있으며, 시스템 서비스로는 네트워크 관리자인 NetworkManager, IPC 버스인 Dbus 등이 있다. 또한 Init은 시스템의 관리를 한다. 대표적으로 시스템 서비스, 커널 등에서 발생하는 로그를 한데 모아서 저널링 하는 기능이 있다. 마지막으로 Init은 데몬 프로세스나, 부모가 죽어서 고아가 된 프로세스의 부모가 된다. 이 덕분에 리눅스의 모든 프로세스는 (Init을 제외하고) 모두 부모 프로세스를 가지게 된다.
백그라운드 서비스와 시스템 서비스를 구분하는 명확한 기준은 없다. 여기서는 시스템 기능을 구성/관리하는 역할을 하는지, 어플리케이션 수준에서 동작하는지에 따라 임의 구분하였다.
단 이러한 작업들은 Init 프로세스 혼자서 수행하는 것은 아니고, 시스템 서비스들의 도움을 받아서 수행한다. 또한 위 그림은 Systemd를 기준으로 하였기 때문에 Upstart, SysV 등 다른 Init 시스템과 다른 부분이 있을 수 있다. (Init 시스템들에 대한 구분은 아래 "1.3 리눅스에서의 Init 시스템" 참조)
1.2 Init의 동작 플로우
Init의 동작 과정을 아주 단순화 하면 다음과 같다.
1. 파일 시스템 초기화 (파일 마운트, 스왑 디바이스 관리, 가상 파일 시스템 마운트 등)
2. 네트워크 및 기본적인 시스템 동작을 위한 시스템 서비스 실행
3. 백그라운드 서비스 실행
4. GUI 쉘 실행
위는 아주 개략화한 Init 프로그램의 동작이다. 리눅스 상에는 다양한 Init 프로그램이 있는데, 이들의 동작을 일반화 하기는 어렵다. 다음 포스트에서 대표적인 Init 프로세스인 Systemd를 다룰 때, Systemd의 동작 플로우에 대해 자세히 다루도록 하겠다.
1.3 리눅스에서의 Init 시스템
앞에서도 언급하였듯이 리눅스에는 다양한 Init 프로그램이 있다. 대표적으로는 오랜 역사를 가진 SysV, Ubuntu에서 사용되던 Upstart, 임베디드에서 종종 사용되는 runit, 그리고 가장 강력하며 오늘날 가장 널리 사용되는 Systemd가 있다. 각 Init 시스템은 아래와 같은 특징들을 가지고 있다.
init 시스템
특징
비고
SysV
- initrc 파일을 통해서 시스템 서비스와 백그라운드 서비스를 실행 -
가장 오래된 Init 시스템
Upstart
- 이벤트 기반의 서비스 관리 - 캐노니컬은 왜 자꾸 이런 갈라파고스같은 서비스를 만드냐...
Ubuntu에서 사용되던 Init 시스템 (현재는 Systemd로 변경)
Runit
- 부팅 / 셧다운시 속도가 빠름 - 작은 코드베이스를 가졌으며, 포팅에 용이
가장 가벼운 Init 시스템, 임베디드 분야에서 사용
Systemd
- 서비스를 "등록"하여 실행 - 이벤트 기반의 서비스 관리 - 저널링, 알람 등 자체적으로 다양한 기능 제공 - 다양한 시스템 관련 라이브러리(sdbus, sd-event 등) 제공
가장 많이 사용되며, 가장 기능이 많은 Init 시스템
이후 포스트에서는 가장 대중적이며, 많은 기능을 가지고 있는 Systemd에 대해서 좀 더 자세히 다루도록 하겠다.
Radamsa는Oulu University Secure Programming Group이 개발한 퍼즈 테스팅 도구이다. 이 도구를 활용하여 소프트웨어 제조사나 개인 개발자들이 보다 손쉽게 소프트웨어의 강건성(robustness) 테스트를 수행할 수 있도록 돕기 위한 취지로 개발되었다. 기존에 출시되어있던 유사한 프로그램들은 설치 자체가 굉장히 복잡하고, 개별 프로젝트에 적용하기 위해서 수많은 추가작업이 필요하다는 단점이 있었다. 이러한 문제점에 착안하여 새롭게 개발한 도구가 바로 Radamsa이다.
Radamsa는 커맨드라인 기반으로 작동할 수 있으며, 샘플 파일을 주입하면 자동으로 변이(mutated)된 결과물을 생산해준다. 그러므로 이 도구는 mutation-based fuzzer라고 구분할 수 있겠다.
이 도구는 심지어 TCP Client 또는 서버로써 사용할 수도 있다. 즉, TCP 연결을 수립한 상태에서 서버 또는 클라이언트의 입장에서 mutation된 입력값을 송수신하게 만드는 것이다.
Radamsa는 하나의 패키지 안에 포함된 다수의 fuzzer를 통칭한다. 단순히 bit를 임의로 몇번 바꾸는 것에 그치지 않고, 샘플 파일의 구조를 분석하여 보다 색다른 퍼징 기법에 적용할 방안을 찾는다. 이러한 기술의 성과는 실제로 효과적이어서, real world의 다수의 소프트웨어에서 흥미로운 취약점들을 도출해내었다.
Radamsa는 무료로 사용할 수 있는 응용 프로그램이며, 필요한 경우 원본 소스코드를 다운로드 받아 각자의 용도에 받게 개조하여 사용하는 것 또한 허용된다. 소스코드는 MIT License를 따라 관리되고 있다.
사용법
Radamsa는 Windows 및 리눅스 용으로 prebuilt된 바이너리 형태가 제공되며, 자신의 환경에 알맞도록 직접 컴파일하여 사용할 수 있도록 소스코드 방식으로도 지원된다. 코드는 아래의 방법으로 얻을 수 있다.
위와 같이 echo "aaa" 명령어의 결과를 radamsa로 전달했더니 처음에는 a라는 문자가 하나 더 붙는 형태로 나타났지만 여러번 재수행할때마다 새로운 방식으로 결과물이 mutate되는 것을 확인할 수 있다. 기본적으로는 /dev/urandom을 사용해서 난수적 흐름을 주입하는 것으로 알려져 있다.
Radamsa는 퍼즈 테스팅을 자동화할 수 있도록 하기 위해 다양한 환경을 제공한다. 특히 command-line 파라미터를 이용해서 원하는 숫자값을 자동으로 계속 생성해낼 수 있다. 그리고 입력으로 주입되는 seed 값을 이용해서 지속적인 변화 흐름을 만들어낼 수 있다. 다만 target monitoring을 기본적으로 지원하지는 않는다. 개발진은 이를 도울 수 있는 shell script example을 readme 파일을 통해 간단히만 설명하고 있다. 이를 참고하여 사용자가 직접 관련 기능을 구현해야 한다.
Radamsa는 샘플파일을 이용해 mutation 기능을 수행한다. 따라서 mutation 기반이기 때문에 모델을 분석하여 data를 스스로 generating 하는 방식은 아니다.
더욱 자세한 설명은 아래의 논문을 참고하면 된다.
An Evaluation of Free Fuzzing Tools 에서 발췌한 Radamsa 도구 평과결과 요약
Yes. Support is available and the project is still alive.
Environmental requirements
Yes. Radamsa runs under Windows, Mac OS X, Linux, and OpenBSD.
아래는 Radamsa를 통해 실용적으로 얼마나 많은 이득을 취할 수 있는지에 대한 평가이다
Practical features criterionPossible advantage
Automation support
Maybe. Supports generating multiple mutations and also TCP connections.
Target monitoring support
No. No monitoring support.
Customization options
Yes. Can control the samples, seed, mutations, patterns and generators. Also source code is available.
아래는 Radamsa가 퍼징하는 방식에 대한 설계적 탁월성을 뜻한다
Intelligence of the fuzzing criterionPossible advantage
Is the data generated or mutated, or totally random
Yes. The data is mutated from the input samples.
Does the fuzzer utilize fuzzing heuristics
Yes. The mutations include both random and smart mutations.
Creating a model for data generation
No.
결론
Radamsa는 아주 간단하면서도 꽤나 강력한 fuzzer이며, 개발자가 자신의 구미에 맞게 적절히 수정하여 사용할 수 있다는 장점을 가지고 있다. 스스로 적절한 퍼즈 테스팅 구조를 수립하고, 그에 알맞게 구현을 변경할 수 있는 개발자들에겐 굉장히 좋은 도구일 것이다. target application에 대한 monitoring 기능은 꼭 추가적으로 제작을 해서 사용하는 것이 좋을 것이다.
아래 내용은 논문 [The Art, Science, and Engineering of Fuzzing: A Survey]를 기반으로 정리한 내용이다. 논문 리뷰는 이 링크에서 확인할 수 있다.
Summary
Grey-box Fuzzer
Open-sourced
In-memory Fuzzing
Seed Scheduling
Mutation
Coverage-baesd Crash Traige
Evolutionary Seed Pool Update
Seed Pool Culling
Instrumentation
AFL은 한 가지 이상의 instrumentation 방법을 사용하는 대표적인 퍼저다.
static instrumentation
afl 전용 컴파일러를 이용해 소스 코드 수준의 정적 instrument 코드를 삽입한다.
dynamic instrumentation
실행 가능한 코드를 PUT 내부에서 instrument 하거나(default 옵션) 실행 가능한 코드를 PUT나 외부 라이브러리에서 instrument 한다(AFL_INST_LIBS 옵션).
* AFL_INST_LIBS 옵션은 실행되는 코드를 모두 instrument 하는 것인데, 외부 라이브러리의 코드에 대한 커버리지 정보도 포함할 수 있어서, 더 완전한 커버리지 정보를 제공한다. 이는 AFL이 외부 라이브러리 함수에서 추가적인 경로를 퍼징하도록 도와준다.
AFL과 그 하위(AFL 계보 퍼저들)의 퍼저는 PUT의 모든 branch instruction을 instrument해서 branch coverage를 계산한다
In-memory fuzzing
GUI처럼 복잡한 프로그램은 프로세스를 생성하고 입력을 전달하기까지 수 초가 소요된다. 이런 프로그램을 퍼징하기 위해 GUI 초기화가 완료된 후에 메모리 스냅샷(snapshot)을 찍는 접근 방식이 존재한다. 새로운 테스트 케이스를 퍼징하기 위해, 테스트 케이스를 메모리에 집접 쓰고 실행하기 전에, 메모리 스냅샷을 복원할 수 있다. 클라이언트-서버간의 상호 작용이 많은 네트워크 응용프로그램을 퍼징할 때도 이런 접근 방식을 사용할 수 있다.
AFL은 초기 실행의 코스트를 줄이기 위해 fork server를 사용한다. fork server는 모든 fuzz iteration에 대해 새로운 프로세스를 fork 한다. 즉 각 fuzz iteration마다 이미 초기화 과정이 끝난 상태의 프로세스를 fork 하여 퍼징할 수 있다.
Execution Feedback
AFL의 minset은 각 branch에 지수적(:logarithm)인 카운터가 있는 branch coverage를 기반으로 한다. 그 이유는 branch 카운터가 몇 배 차이로 다를 때만 차이가 있다고 인지하도록 설정한 것이다.
[AFL whitepaper의 "2) Detecting new behaviors"에서 확인할 수 있다.]
seed trimming
AFL은 어떤 시드가 동일한 커버리지를 달성하도록 유지하면서, 그 시드의 일부분을 제거하는 코드 커버리지 instrumentation을 사용한다.
FCS Algorithms
AFL은 FCS problem에 EA(Evolutionary Algorithm)을 사용한다. 즉 fitness의 가치가 있는 configuration set을 유지한다.
AFL은 control-flow edge를 실행하는 configuration 중, 가장 빠르고 가장 작은 configuration 입력을 포함하는 configuration을 가장 효과적(AFL에서는 favorite라는 용어를 사용)이라고 판단한다. AFL은 config 큐를 원형 큐(circular queue) 형태로 유지하면서 다음으로 효과적인 configuration을 선택하고, 일정한 횟수만큼 실행한다.
-i와 -o는 각각 input/output 디렉토리를 지정해 준 것이다. --은 타겟 프로그램의 이름과 인자를 전달하기 위함이다.
즉 -dcf 옵션으로 dact를 퍼징하겠다는 의미다.
퍼징을 시작하면 아래와 같이 초기화 작업 이후 깔끔한 모습으로 상황을 보여준다.
아래 사진은 11분간 퍼징을 했을 때 상황이다.
Fuzzing for 11 minutes
unique crash가 27개 발견되었다.
이제 퍼징을 멈추고 취약점 종류를 살펴보자.
see crash
ls ~/out/crashes/
퍼징에 사용한 dact_afl 바이너리도 reproduce에 사용할 수 있지만, 더 많은 정보를 제공하는 ASAN을 이용하겠다.
아래와 같이 ASAN instrumentation 코드를 삽입하여 dact를 빌드 하자.
build dact with ASAN
cd ~/dact_dir/
make clean
CC="clang -fsanitize=address" CXX="clang++ -fsanitize=address" ./configure
make
mv ~/dact_dir/dact ~/dact_asan
이렇게 빌드 한 dact_asan으로 crashing input을 실행할 경우 crash가 발생한 이유를 자세히 확인할 수 있다.
crash 원인만 간단히 살펴보기 위해 dact_asan을 이용해 crash log를 생성하자.
make crash log w/ asan
for file in ~/out/crashes/*; do;
echo Input: $file >> ~/crash.log;
~/dact_asan -dcf $file 2>> ~/crash.log;
done;
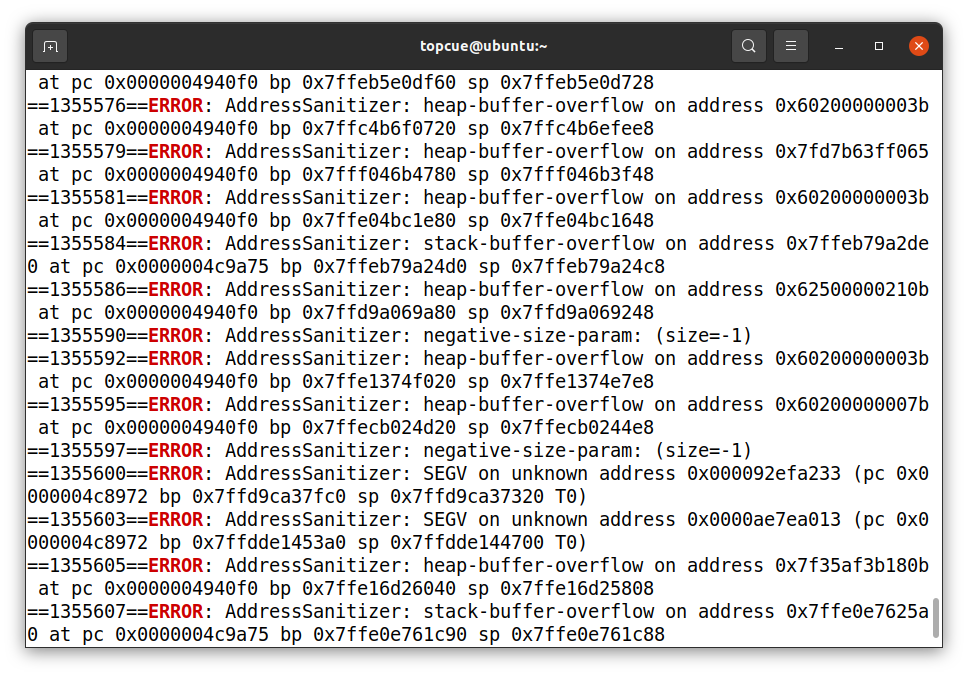
아래와 같이 grep을 이용해 ASAN이 분류해 준 취약점 원인을 확인할 수 있다.
grep ERR
grep ERROR ~/crash.log
crash log
이들 중 스택 버퍼 오버플로우만 필터링하자.
grep stack-buffer-overflow
$ grep ERROR ~/crash.log | grep stack
==1355737==ERROR: AddressSanitizer: stack-buffer-overflow on address 0x7ffc9c54a180 at pc 0x0000004c9a75 bp 0x7ffc9c549870 sp 0x7ffc9c549868
==1355760==ERROR: AddressSanitizer: stack-buffer-overflow on address 0x7ffdec592a20 at pc 0x0000004c9a75 bp 0x7ffdec592110 sp 0x7ffdec592108
스택 버퍼 오버플로우 취약점을 트리거 하는 crashing input 두 개가 있다.
이들이 각각 어떤 파일인지 확인하기 위해 crash.log 파일을 열고 id를 확인하자.
detail
vi ~/crash.log
# search string w/ command mode
/stack-buffer-overflow
crash log detail
==1355760==ERROR: 라인 위로 쭉 올라가면 파일명을 확인할 수 있다.
Input: /home/topcue/out/crashes/id:000026,sig:06,src:000027,op:havoc,rep:8
dact: read: No such file or directory
dact: read: No such file or directory
...
dact: read: No such file or directory
dact: read: No such file or directory
=================================================================
1721 ==1355760==ERROR: AddressSanitizer: stack-buffer-overflow on address 0x7ffdec592a20 at pc 0x0000004c9a75 bp 0x7ffdec592110 sp 0x7ffdec592108
1722 WRITE of size 8 at 0x7ffdec592a20 thread T0
1723 #0 0x4c9a74 in dact_process_file /home/topcue/dact-0.8.42/dact_common.c:478:40
1724 #1 0x4cdbf7 in main /home/topcue/dact-0.8.42/dact.c:689:8
1725 #2 0x7f38a1a330b2 in __libc_start_main /build/glibc-eX1tMB/glibc-2.31/csu/../csu/libc-start.c:308:16
1726 #3 0x41c4ad in _start (/home/topcue/dact_asan+0x41c4ad)
dact: read: No such file or directory
dact: read: No such file or directory
...skip...
dact: read: No such file or directory
dact: read: No such file or directory
address sanitizer가 출력한 구분선이며 이후 아래 모든 내용은 address sanitizer가 출력한 내용이다.
==1356226==ERROR: AddressSanitizer: stack-buffer-overflow on address 0x7fffa42eed60 at pc 0x0000004c9a75 bp 0x7fffa42ee450 sp 0x7fffa42ee448
ASAN이 감지한 취약점이 stack-based buffer overflow라는 사실을 알 수 있다.
또한 pc, bp, sp와 같은 레지스터 값을 출력해 준다.
WRITE of size 8 at 0x7fffa42eed60 thread T0
#0 0x4c9a74 in dact_process_file /home/topcue/dact-0.8.42/dact_common.c:478:40
#1 0x4cdbf7 in main /home/topcue/dact-0.8.42/dact.c:689:8
#2 ...skip...
어떤 thread에서 버그가 발생했는지 알려준다.
그 아래는 스택을 backtrace 해주며 취약점이 존재하는 정확한 라인 넘버를 제시한다.→ dact_common.c:478
Address 0x7fffa42eed60 is located in stack of thread T0 at offset 2304 in frame
#0 0x4c50ff in dact_process_file /home/topcue/dact-0.8.42/dact_common.c:249
This frame has 16 object(s):
[32, 36) 'cipher.addr'
[48, 192) 'filestats' (line 250)
[256, 2304) 'file_extd_urls' (line 252) <== Memory access at offset 2304 overflows this variable
[2432, 2433) 'algo' (line 253)
...skip...
[2640, 2644) 'x' (line 265)
[2656, 2664) 'offset' (line 266)
stack frame 정보를 제공한다. frame에 16개의 object들이 있으며 [256, 2304) 'file_extd_urls'의 256바이트부터 2303바이트까지 범위를 의미한다.
그런데 offset 2304에 접근하려 해서 overflow로 분류되었다.
Shadow bytes of crash
스택에 guard page를 넣어뒀는데 [f2]에 접근하다가 다른 object를 침범했다.